LLM 추론 속도 4배↑ 전력 2.2배↓
트랜스포머·맘바 결합한 메모리 내 연산 구조 구현
MICRO 2025서 공개, 글로벌 주목
AI가 인간의 언어를 이해하고 처리하는 시대, 그 속도를 좌우하는 것은 결국 '반도체의 두뇌'다.
KAIST 연구진이 거대언어모델(LLM)의 연산 효율을 극대화하는 새로운 AI 반도체 핵심 기술을 세계 최초로 구현하며 글로벌 반도체 연구의 판을 흔들었다.

KAIST 전산학부 박종세 교수 연구팀은 미국 조지아공과대학교(Georgia Institute of Technology), 스웨덴 웁살라대학교(Uppsala University)와 공동으로 트랜스포머(Transformer)와 맘바(Mamba)의 장점을 결합한 '트랜스포머·맘바 하이브리드 모델' 기반의 메모리 내 연산 반도체 'PIMBA(Processing-in-Memory Acceleration)'를 개발했다고 17일 밝혔다.
연구는 LLM의 처리 속도를 최대 4.1배 끌어올리고, 에너지 소비를 평균 2.2배 줄이는 데 성공했다. 이는 기존 GPU 기반 시스템이 데이터를 메모리 밖으로 이동시켜 연산하는 방식에서 벗어나, PIMBA가 데이터를 옮기지 않고 메모리 내부에서 직접 계산을 수행하기 때문이다. 데이터 이동 시간이 사라지면서 연산 속도는 크게 향상되고, 전력 소모는 획기적으로 절감됐다.
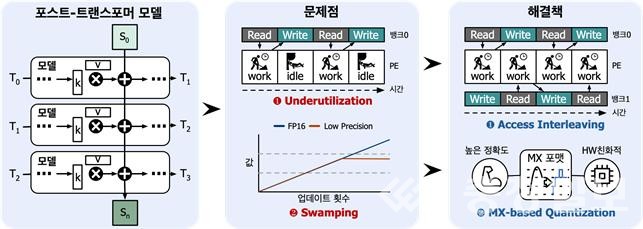
현재 ChatGPT, GPT-4, Claude, Gemini, Llama 등 글로벌 LLM 모델 대부분은 문장을 한 번에 처리하는 트랜스포머 구조를 기반으로 작동한다. 하지만 모델이 커질수록 연산량이 폭증하고, 메모리 병목 현상(memory bottleneck)이 심화돼 속도 저하와 에너지 비효율이 문제로 지적돼 왔다. 이를 보완하기 위해 최근 등장한 순차형 기억 모델 '맘바(Mamba)' 구조가 주목받았지만, 여전히 전력 효율의 한계가 있었다.
박 교수팀은 이러한 구조적 한계를 해결하기 위해 트랜스포머의 병렬 처리 능력과 맘바의 기억 효율을 결합하고, 연산을 메모리 내부에서 수행하도록 설계한 것이다. 그 결과 PIMBA는 기존 AI 반도체의 처리 속도를 획기적으로 높이면서도 에너지 소비를 크게 줄여, 초거대 AI 모델 운용의 가장 큰 병목을 해결할 기술로 평가받고 있다.
이번 연구 성과는 오는 10월 20일 서울에서 열리는 세계 최고 권위의 컴퓨터 구조 학술대회 '제58회 국제 마이크로아키텍처 심포지엄(MICRO 2025)'에서 발표될 예정이다. 앞서 '31회 삼성휴먼테크 논문대상'에서 금상을 수상하며 그 우수성을 인정받았다.
연구는 정보통신기획평가원(IITP), 인공지능반도체대학원 지원사업, 과학기술정보통신부 ICT R&D 프로그램, 한국전자통신연구원(ETRI)의 공동 지원으로 진행됐으며, EDA 툴은 반도체설계교육센터(IDEC)의 도움을 받아 개발됐다.
박 교수는 "AI 모델이 점점 거대해지는 시대에, 효율적인 연산 구조는 선택이 아닌 필수"라며 "PIMBA는 메모리 중심의 새로운 패러다임을 열어 초거대 AI 운용의 전력 문제를 근본적으로 해결할 것"이라고 말했다.
성과는 반도체와 AI의 경계를 잇는 기술적 도약이자, 한국이 차세대 AI 반도체 시대의 선두로 나아갈 수 있음을 입증한 상징적 결과다. /대전=이한영기자